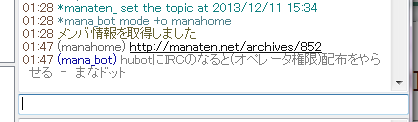
よくあるやつ。
request = require 'request' cheerio = require 'cheerio' module.exports = (robot) -> robot.hear /(h?ttps?:\/\/[-a-zA-Z0-9@:%_\+.~#?&\/=]+)/i, (msg)-> request { uri: msg.match[1] }, (error, response, body)-> return if error $ = cheerio.load body.replace(/<!\[CDATA\[([^\]]+)]\]>/ig, "$1") title = $("title") robot.adapter.notice msg.envelope, "#{title.text()}" if title
URLにマッチしたら、それをそのままrequestして、取得したbodyをcheerioでパースし、タイトルタグの内容を喋らせるだけ。かんたん。
追記
URL先の文字コードがUTF-8以外だと文字化けするので、iconv使ってこんな風にした。
request = require 'request' cheerio = require 'cheerio' iconv = require 'iconv' convertEncode = (body) -> charset = body.toString('ascii').match /<meta[^>]*charset\s*=\s*["']?([-\w]+)["']?/i return new iconv.Iconv(charset[1], 'UTF-8//TRANSLIT//IGNORE').convert(body) if charset body module.exports = (robot) -> robot.hear /(h?ttps?:\/\/[-\w@:%\+.~#?&\/=]+)/i, (msg)-> uri = msg.match[1] request { uri: uri, encoding: null }, (error, response, body)-> return if error $ = cheerio.load convertEncode(body).toString().replace(/<!\[CDATA\[([^\]]+)]\]>/ig, "$1") title = $("title") robot.adapter.notice msg.envelope, "#{title.text()}" if title
UTF-8以外のWebサイトなんていい加減存在しないかと思いきや、大手ニュースサイトがそうだったりするので大変困る。
追記2 (12/20)
titleタグが改行含んでたりすると、うまく喋ってくれなかったのでしゃべるところを以下のようにしてみた。
if title titleText = title.text().replace(/^[\s\n]+/, '').replace(/[\s\n]+$/, '') robot.adapter.notice msg.envelope, "#{titleText}"